Luna v2: The Orchestrator Takes Charge

The last post about Luna ended with a known problem: one sentence, two agents, one dropped task. The router picked a lane and stayed in it. Luna v2 fixes that.
It is live. Here is what changed.
The New Architecture
The single match statement is gone. In its place: an orchestrator and a set of worker agents.
The orchestrator receives every message, understands intent, and decides who handles it. Workers get invoked in one of two modes:
- Ask - the worker executes and reports back to the orchestrator, which synthesises a final response.
- Delegate - the worker responds directly to the user. No round-trip.
The distinction matters. A task that spans Notion and Google Calendar goes through Ask mode; both agents run, the orchestrator assembles the result. A quick Q&A gets delegated immediately. The right tool for the right depth of task.
This is what LangGraph was always capable of. The v1 graph just did not use it.
A note on latency. Luna is an ambient agent. Fire a request and move on. The priority has always been task completion at minimum cost, not response speed. With that context, the numbers are fine: basic responses around 1.5 seconds, delegated tasks like a calendar query around 4 seconds. There is a well-known trilemma in AI-systems design: performance, cost, and speed. Pick two. This stack is optimized for the first two. Speed is acceptable collateral.

Feedback Is Now a Tool
There was a quiet failure mode in v1 that kept showing up in the logs.
Feedback - thumbs up, thumbs down, corrections, was handled by regex matching. Specific phrases triggered specific logic. It was brittle in exactly the way you would expect from brittle logic: the moment ASR transcribed something slightly off, the match failed and the feedback went nowhere.
The fix was to stop treating feedback as a parsing problem and start treating it as an agent capability. The orchestrator now has a dedicated feedback tool it can call when it detects a correction or rating signal, regardless of exact phrasing. Speech-to-text imperfections become the model’s problem to interpret, not the code’s problem to match.
Fewer silent failures. More reliable feedback loop.
Wispr Flow and the Invisible Interface
Wispr Flow has been taking off lately, and it is worth calling out in this context.
I have been using it heavily across work, writing, and talking to Luna. Going back to typing feels like a downgrade at this point. Speaking is faster, more natural, and closer to how you actually think.
The premise of Luna has always been voice as the primary interface. Wispr Flow gaining this much traction right now is a signal that the broader market is arriving at the same conclusion.
The roadmap writes itself from here. If voice-first tools are breaking out, local ASR is going to get significantly better. Google and Apple are not going to sit this one out. On-device speech recognition will get smarter, faster, and more context-aware. Luna is already built for a world where that is true.
Slack as a Second Channel
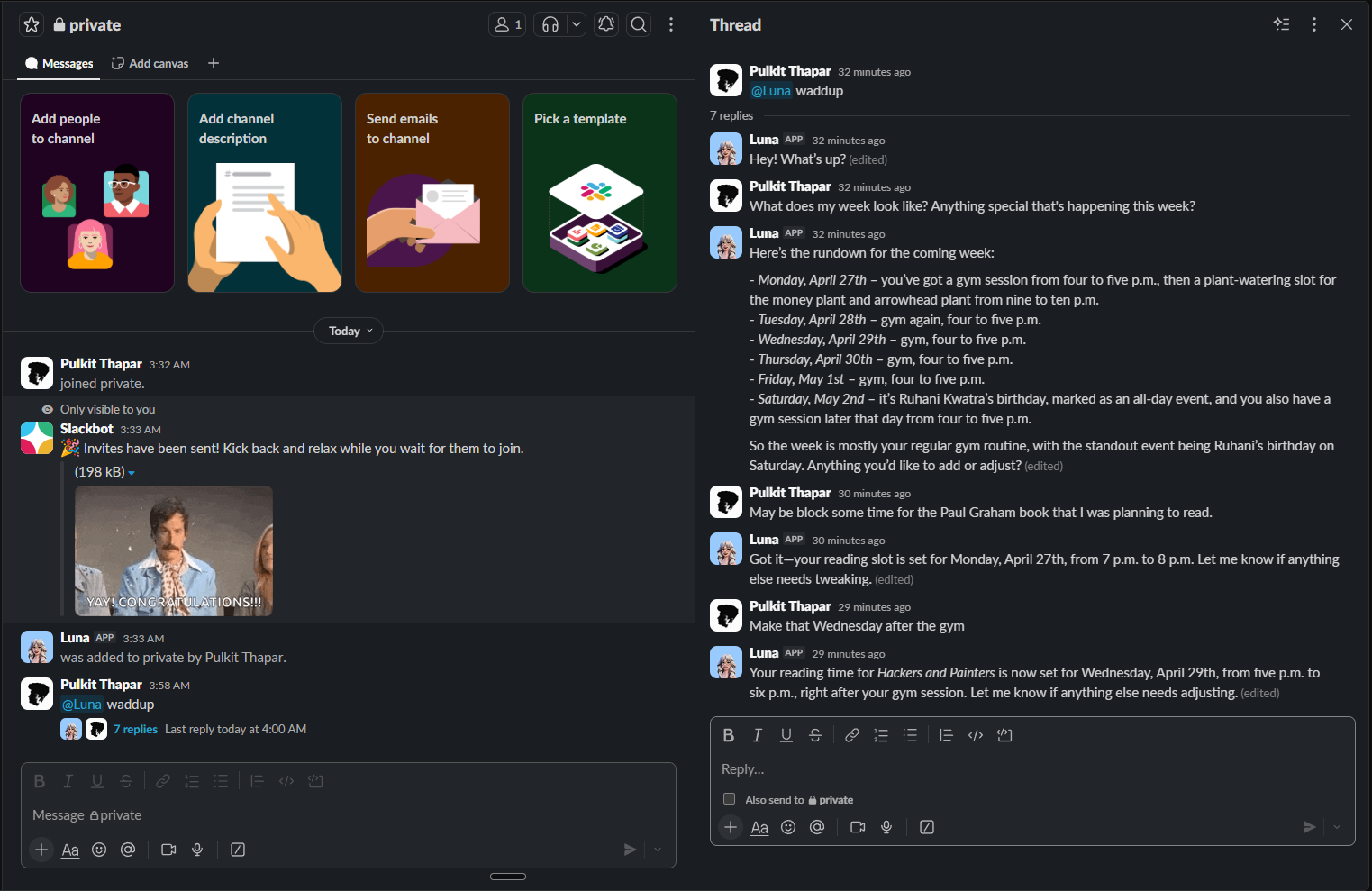
Luna now lives in Slack.
Two reasons this happened:
-
First, I started using Slack seriously and immediately saw the overlap. Luna already knows my Notion workspace, my calendar, my tasks. Having that available in the context where I am already thinking about work is not a nice-to-have, it is the right place for it. Tag Luna in a channel, ask a question, get something done. Same brain, new door.
-
Second, observability. LangSmith handles full traces. But I do not always want to open LangSmith. Sometimes I just want to see what the agent is doing in the background - which tools it called, what it decided, where it went. I am considering writing selective log messages directly to a Slack channel. I control what gets logged. It is a lightweight window into agent behaviour without the overhead of pulling up a full trace.
Luna inside Slack channels is still being tested. Notion queries and calendar lookups are working. More to follow.
One Brain, Three Voices
WhatsApp is the next channel on the list. But adding interfaces is no longer just a routing problem, it is a formatting problem.
Think about it. The iOS shortcut speaks its response out loud. A bullet point in a TTS response sounds like someone reading a list at you. An asterisk sounds like nothing at all. That interface needs plain prose: conversational, natural, the kind of language you would use speaking to someone, not presenting to them.
WhatsApp is different. It is a screen. Line breaks, spacing, maybe a little structure, all of that renders and helps. Slack goes further: work context, larger screen real estate, richer formatting is appropriate and expected.
Same response. Three different contracts for how it gets delivered.
Luna will eventually need to be aware of which channel it is speaking into and shape its output accordingly. Not just what to say, but how to say it. That is the next layer of work before new interfaces get added casually.
Same brain. But different voices for different rooms.
What Is Next
WhatsApp is in progress. The n8n automation layer is next in line. And before any of that ships cleanly, the channel-aware response formatting above has to be solved. You do not want Luna reading markdown bullet points into your AirPods.
The architecture is ready. The voice has to catch up.